자이랜드의 향상된 데이터파이프라인
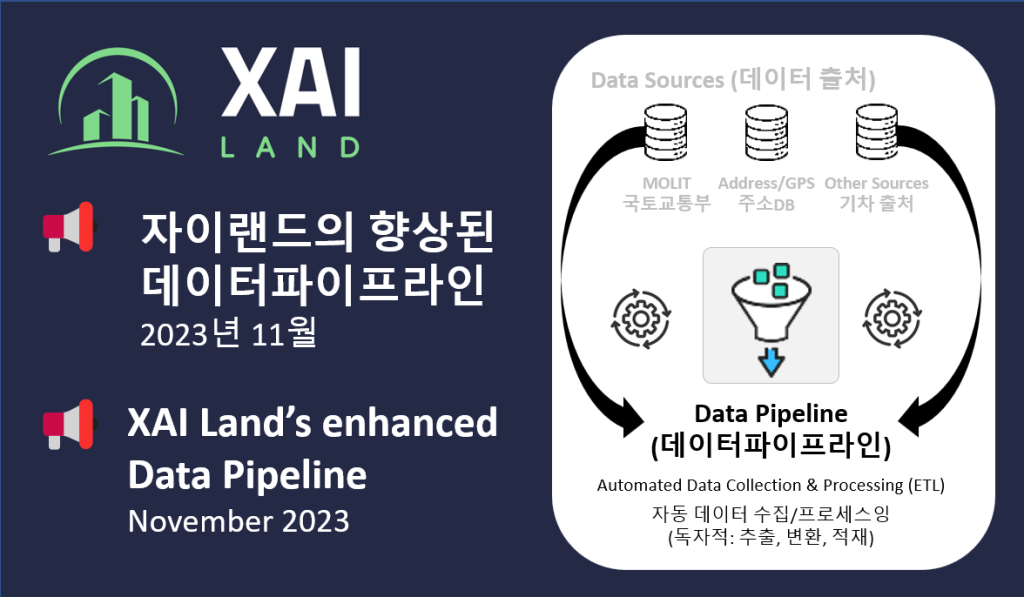
< English follows Korean >
자이랜드는 가장 정확하고 최신의 부동산 평가 및 가격 예측을 제공하기 위해 자동평가 모델(AVM)을 개선하기 위해 끊임없이 노력하고 있습니다. 최근 데이터 팀은 아파트, 오피스텔, 빌라 (연립주택, 다세대주택), 도시형 생활주택에 대한 데이터 파이프라인과 머신러닝 모델을 향상시키기 위해 열심히 노력하고 있습니다.
데이터 처리 및 정제 (청소/클리닝) 개선
자이랜드는 다양한 정부 및 타사 소스/출처로부터 수집해온 원시 데이터의 품질을 향상시키기 위해 상당한 시간과 노력을 투자했습니다. 이는 건물명, 블록명, 층수, 전용면적과 같은 주요 필드를 철저하게 검증하고 정리하는 작업을 포함합니다. 고품질의 입력 데이터는 보다 정확한 모델로 이어집니다. 또한 자사는 데이터 스키마를 통합하여 데이터 일치성 문제를 해결했습니다.
건축물대장 데이터의 경우, 건물명과 블록명 필드에서 변칙을 제거하기 위해 포괄적인 정규 표현식 분석 (Regular Expression) 및 로직을 구현했습니다.
이는 건물 이름 내에서 블록명이 잘못 인코딩된 경우를 해결함으로써 거래 데이터와 건축물대장 데이터 간의 일치율을 높였습니다.
또한, 서로 다른 정부 소스 간의 건축 연도 충돌로 인한 건축물대의 중복 입력, 서로 다른 정부 소스 간의 사유지 충돌로 인해 거래 등 다른 데이터 집합과의 일치가 어려운 문제, 그리고 행정구역명이 변경된 주소의 업데이트 날짜가 달라 데이터 집합 간 주소 불일치와 같은 다양한 버그를 발견하였습니다.
또한 주소DB(JusoDB) API 대신 더 많은 일치성, 낮은 지연성 그리고 전반적으로 더 나은 결과를 제공한 네이버 API 및 카카오 API를 활용하여 지오코딩을 개선했습니다. 이러한 외부 소스를 활용하여 건물명 등 누락된 데이터를 보다 효과적으로 보충할 수 있습니다.
거래 측면에서는, 주소 문자열 (Address string) 일치를 최적화하여 빌라에 대한 세금 데이터 일치율을 50% 이상 높였습니다. 뿐만 아니라, 지역 내 세금 가격의 표준 편차와 같은 새로운 기능을 설계하였고, z-스코어 (z-scores)를 활용하여 비정상적인 데이터 포인트를 감지할 수 있도록 하였습니다. 더불어, 데이터 품질 향상을 위해 도메인 지식과 통계 방법을 결합하였습니다.
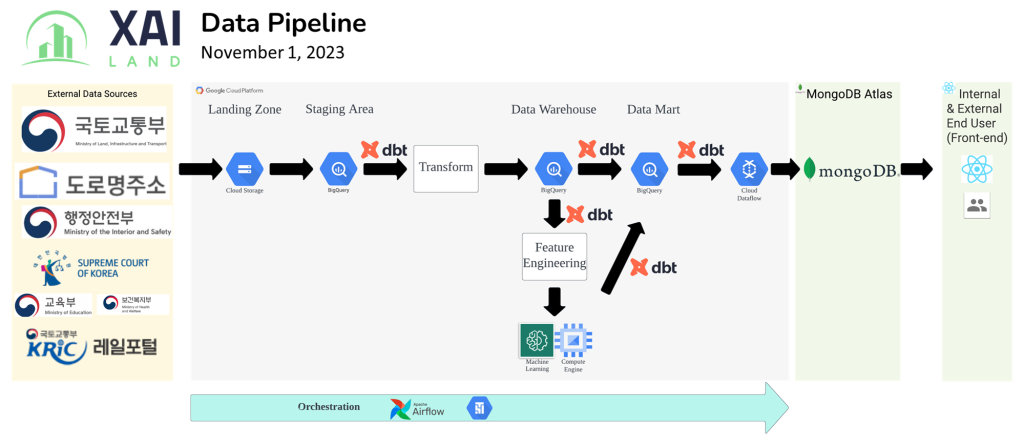
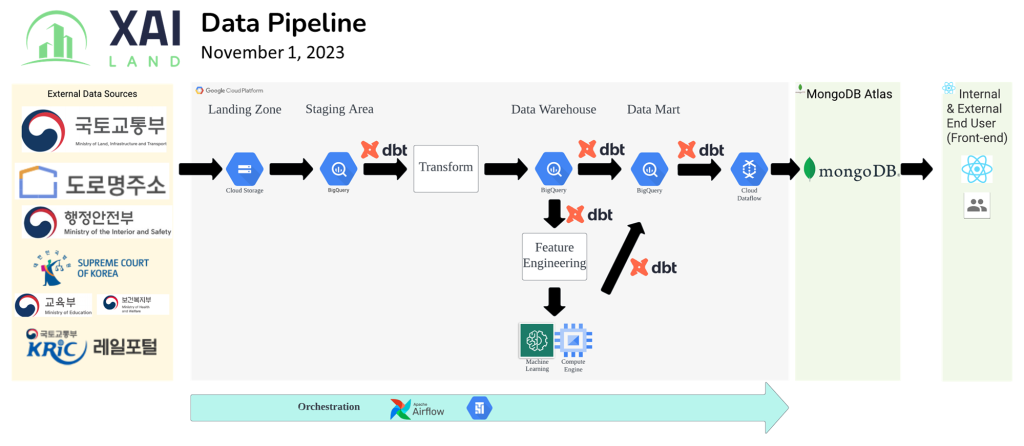
자사는 파이프라인을 완전히 재구성하여 분산된 워크로드에 따라 쉽게 자동화되고 수평적으로 확장할 수 있도록 했습니다. 대부분의 처리와 계산 작업을 수행한 단일 기계 Pandas에서 서버가 없는 분산 컴퓨팅 작업을 수행하는 Google Cloud Platform의 BigQuery로 전환했습니다.
또한 데이터 모델을 신속하게 개발 및 수정할 수 있는 도구인 dbt™를 추가 활용하였습니다. dbt는 CI/CD의 기본 기능을 내장하고 데이터의 가시성을 향상시키는 데 도움을 줍니다. 이러한 모든 사항은 데이터 파이프라인의 품질을 개선하고 데이터를 빠르게 전달하는 데 중점을 두어 더 효율적으로 관리할 수 있도록 도와줍니다.
자이랜드는 최신 시장 데이터를 반영한 가치 평가를 제공하기 위해 자사의 모델을 주간 업데이트합니다. 데이터 파이프라인과 인프라의 최적화로, 새로운 거래 데이터가 수집될 수 있고 몇 시간 내에 모델 재학습이 가능해졌습니다.
이러한 빠른 업데이트 주기는 파이프라인의 각 단계에서 포괄적인 모니터링과 철저한 품질 확인을 통해 가능해졌습니다. 자이랜드는 데이터 변칙에 대한 경보 및 자동 재시도 기능을 구현하여 시스템을 견고하게 만들었으며 사전에 결점을 방지할 수 있도록 하였습니다.
클라우드 기반 인프라를 설계할 때, 확장성과 효율성을 최우선으로 고려했습니다. 해당 시스템은 계속해서 증가하는 데이터 양과 모델 복잡성을 원활하게 처리합니다. 최근 스트레스 테스트 (stress test)결과, 자사의 파이프라인이 소스 데이터를 10배 더 많이 수집하면서도 전체 처리 시간을 단축할 수 있는 것을 확인했습니다.
더 체계적인 데이터를 통해 빌라 건물 유형에 대한 세금 데이터와 거래 데이터 간의 일치율을 크게 높였습니다. 더 많은 일치 데이터는 모델이 가격 책정 패턴을 보다 정확하게 학습하도록 도와줍니다. 뿐만 아니라, 지역 내 세금 가격의 표준 편차와 같은 새로운 기능을 도입하여 변칙 과 이상값을 감지할 수 있도록 했습니다.
모델링 개선
모델링 측면에서, 자이랜드는 하이퍼파라미터에 대한 포괄적인 실험을 수행하여 각 건물 유형과 지역에 맞는 이상적인 구성을 찾아냈습니다. 모델을 지리적으로 클러스터링함으로써 전국 단일 모델 대비 정확도를 더욱 향상시켰습니다.
자이랜드는 XGBoost 하이퍼파라미터를 통해, 추정기 수, 트리의 최대 깊이(maximum tree depth, 그리고 수년간의 거래 내역과 같은 요소에 대한 포괄적인 실험을 진행하였습니다. 최적의 설정은 건물 유형과 지역에 따라 다양했으며, 맞춤 설정의 중요성을 강조했습니다. 하나의 전국 단위 모델을 학습시키는 대신 지리적 근접성에 따라 모델을 클러스터링 하는 방법이 정확도를 향상시킨 것으로 확인되었습니다.
최근 수천 건의 거래에 대한 포괄적인 벤치마킹 결과, 평균적으로 약 95% < 10%의 오차율을 보였으며, 주요 경쟁사들의 성능을 능가하였습니다.
빌라(연립주택/다세대주택) AVM에 대한 개선이 있었지만, 더 나아 지리 가중 회귀분가석 (Geographic Weighted Regression, GWR)와 같은 기술을 활용하여 빌라 모델에 대한 개선을 지속적으로 탐색하고 있습니다. 또한 부동산 경매와 같은 새로운 데이터 소스를 통합하여 모델을 강화하고 고객에게 보다 심층적인 분석을 제공하기 위한 파이프라인을 구축하고 있습니다.
지속적인 데이터 및 모델 개선을 통해 자이랜드는 부동산의 구매자, 판매자 및 금융인이 손쉽게 거래할 수 있도록 도와주는 것뿐만 아니라 한국의 주요 과제 중 일부를 해결하기 위해 가장 정확하고 편향되지 않고 신뢰할 수 있는 AVM을 제공하기 위해 전념하고 있습니다.

데이터파이프라인 결과: 자이랜드 AVM, K*시세·질로우 제쳤다… 정확도 2배 이상 높아
자이랜드의 향상된 AVM 솔루션을 원시 데이터 또는 평가 보고서 형식으로 테스트하여 실험 결과를 확인하고자 하거나 자체 내부 테스트를 희망하시는 경우, 귀하의 신상 정보와 회사 정보, 희망하는 테스트 일정 등을 contact@xai.land로 보내주시기 바랍니다.
계속해서 개선되는 AVM을 기대해주세요.
자이랜드(주)에 대하여
자이랜드는 한국인이 어디에 있든 사기, 불공정 관행, 과다 청구의 위험 없이 완전한 투명성을 바탕으로 안심하고 부동산 금융과 거래를 할 수 있는 세상을 꿈꿉니다.
가장 정확한 AVM을 통해 부동산 거래를 지원하며, 정확한 가치 평가와 투명한 거래 프로세스를 보장하는 것이 우리의 사명입니다. 우리는 부동산 사기를 예방하고 공정한 가격을 보호하며, 국내외 모든 부동산 관련 과정에서 원활하고 안전한 경험을 제공하기 위해 끊임없이 노력하고 있습니다.
더 자세한 내용을 원한다면, https://xai.land/ 를 방문하거나 LinkedIn ( https://www.linkedin.com/company/18522292/ ) 또는 Facebook ( https://www.facebook.com/xailand/ )의 업데이트를 팔로우하십시오.
주요 요약은 Linktree(https://linktr.ee/xai_land)에서도 한눈에 확인하실 수 있습니다.
XAI Land’s enhanced Data Pipeline
At XAI Land, we are constantly working to improve our automated valuation models (AVMs) to provide the most accurate and up-to-date real estate valuations and price predictions possible. Recently, our data team has been hard at work enhancing our data pipelines and machine learning models for apartments, officetels, and villas.
Data Processing/Cleaning Improvements
We invested significant time into improving the quality of the raw data we ingest from various government and third-party sources. This included extensive verification and cleaning of key fields like building names, block names, floor numbers, and private areas. Higher quality input data translates to more accurate models. We also unified data schemas to resolve inconsistencies.
For registry data, we implemented extensive regular expression parsing and logic to clean anomalies in building name and block name fields.
This allowed us to resolve cases where block name was erroneously encoded within building name, increasing our matching rate between transactions and registry data.
There were other bugs that we discovered such as construction year conflicts between different government sources that resulted in duplicate registry entries, private area conflicts between different government sources that resulted in difficulty matching data from other datasets such as transactions, and mismatches in address between datasets due to different update dates for addresses that had a change in their administrative district names.
We also improved geocoding by moving away from JusoDB (주소DB) API and leveraging more of Naver API and Kakao API which yielded more matches, less latency, and overall better results. We are able to fill in more gaps of missing data such as building name also by leveraging these third party sources.
On the transaction side, we optimized address string matching, increasing matched tax data by over 50% for villas. We also engineered new features such as standard deviation of tax prices within a neighborhood to detect anomalous data points using z-scores. Domain knowledge and statistical methods were combined to improve data quality.
We’ve completely reworked our pipeline so that it can be easily automated and scales horizontally with distributed workloads. We’ve moved from the majority of the processing and compute done by Pandas on a single machine to serverless, distributed compute on BigQuery within Google Cloud Platform.
We have also added use of the tool dbt™ that enables the team to quickly develop and modify data models, contains built in functionality for CI/CD, and help improve observability of our data. All these things help us to better manage our data pipeline with a focus on quality and speed of delivery.
To provide valuations that reflect the latest market data, we now update our models on a weekly basis. New transaction data is ingested and available for model retraining within hours thanks to optimizations in our data pipeline and infrastructure.
Our rapid update cadence is enabled by extensive monitoring and rigorous quality checking at each stage of the pipeline. We’ve implemented alerts for data anomalies and automated retries to make the system robust and fault-tolerant.
Scalability and efficiency were top priorities while designing our cloud-based infrastructure. The system seamlessly handles increased data volumes and model complexity without delays. Recent stress testing showed our pipeline was able to ingest a 10X increase in source data while reducing overall processing time.
With cleaner data, we increased the matching rates between tax data and transaction data substantially for villa building types. More matched data enables the models to learn pricing patterns better. We also engineered new features like standard deviations of tax prices within neighborhoods to detect anomalies and outliers.
Modeling Improvements
On the modeling side, we experimented extensively with hyperparameters, finding ideal configurations for each building type and region. Clustering models geographically further enhanced accuracy over a single nationwide model.
We experimented extensively with XGBoost hyperparameters like number of estimators, maximum tree depth, and years of transaction history for feature selection. Optimal configurations varied across building types and regions, highlighting the importance of customization. Clustering models by geographic proximity rather than training one nationwide model improved accuracy.
Extensive benchmarking on thousands of recent transactions showed approximately 95% <10% error rates on average, exceeding performance of leading competitors.
Although we saw improvements to our villa AVMs, we are continuing to explore enhancements to our villa model by using techniques like Geographically Weighted Regression (GWR). We are also building pipelines to incorporate new data sources like real estate auctions to enrich our models and provide a more in-depth analysis to customers.
Through continuous refinement of our data and models, XAI Land remains committed to delivering the most accurate, unbiased, and reliable AVMs possible to not only help buyers, sellers, and financiers of real estate transact with ease, but also, to tackle some of South Korea’s biggest challenges.
Data pipeline results: XAI Land AVM outperforms K*시세·Zillow…More than twice as accurate
If you may wish to test XAI Land’s enhanced AVM solution to verify the results of this test or to conduct your own internal testing, please email XAI Land at (contact@xai.land) with a brief explanation of who you are, your organization, and when you may wish to test XAI Land’s AVM solution.
Expect regular updates as we iterate and continue to improve our AVMs.
About XAI Land
XAI Land envisions a world where Koreans, no matter where they may call home, can confidently finance and transact real estate with complete transparency, free from the risks of fraud, unfair practices, or being ripped off.
Our mission is to support real estate transactions with the most accurate automated valuation models (AVMs), ensuring accurate valuations and transparent transaction processes. We are constantly striving to prevent real estate fraud, protect fair prices, and provide a seamless and secure experience in all real estate-related processes, both domestically and internationally.
For more information, visit https://xai.land/ or follow updates on LinkedIn (https://www.linkedin.com/company/18522292/) or Facebook (https://www.facebook.com/xailand/).
You can also see the main summary at a glance on Linktree (https://linktr.ee/xai_land).
You Might Like


